Apollo V4: From Benchmarks to Everyday Trust


Apollo V4 extends industry-leading deepfake detection into the full complexity of real-world communication. Building on Apollo's position at the top of public benchmarks, V4 goes further, delivering robust protection across the compression pipelines of Microsoft Teams, Google Meet, and Zoom, through codec degradation and network variability, and across 40+ languages including underrepresented dialects. For organisations safeguarding against AI voice fraud, this means continuous, reliable detection in live communication channels, with the consistency and low false positive rate needed to act on every alert with confidence.

Recap & Overall Picture
With Apollo V3, we set a new standard in audio deepfake detection, outperforming both open-source and commercial solutions across major public benchmarks in accuracy, F1 score, and equal error rate. You can see Apollo V3's benchmark results below. For a full breakdown of how we evaluated V3 against the competition, see our earlier post: Introducing Apollo: Setting a New Record in Voice Deepfake Detection Accuracy.
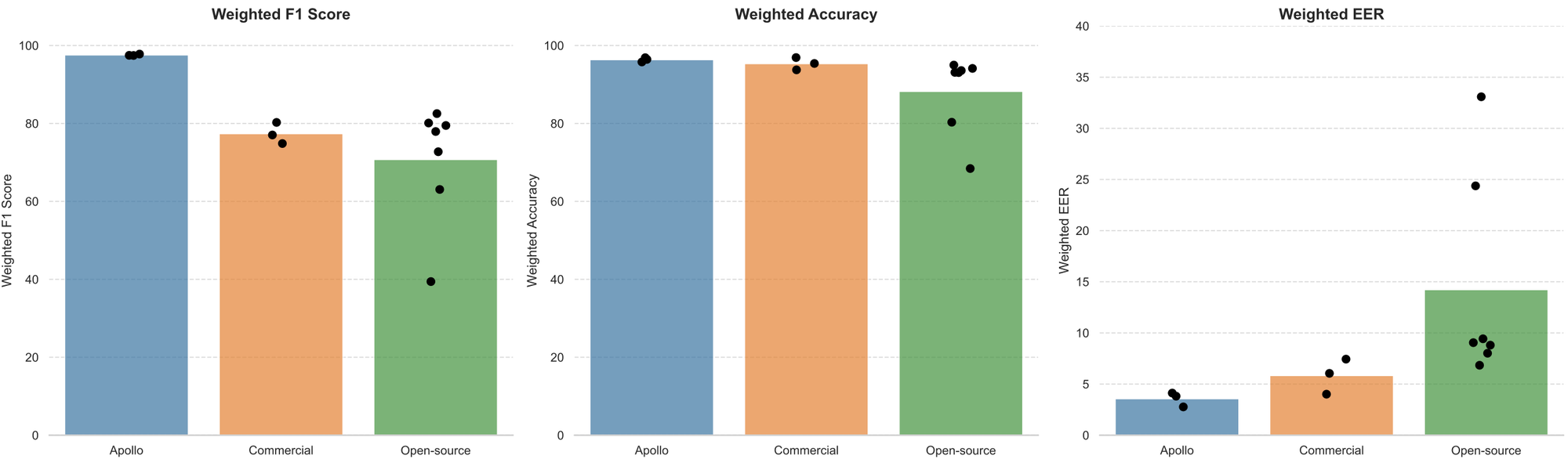
But winning on benchmarks is only half the battle. Public datasets, while valuable for comparison, don't capture the full complexity of real-world deployment: the distortion introduced by meeting platforms, the degradation from network packet loss, the diversity of languages spoken worldwide, or the constant emergence of new generation methods.
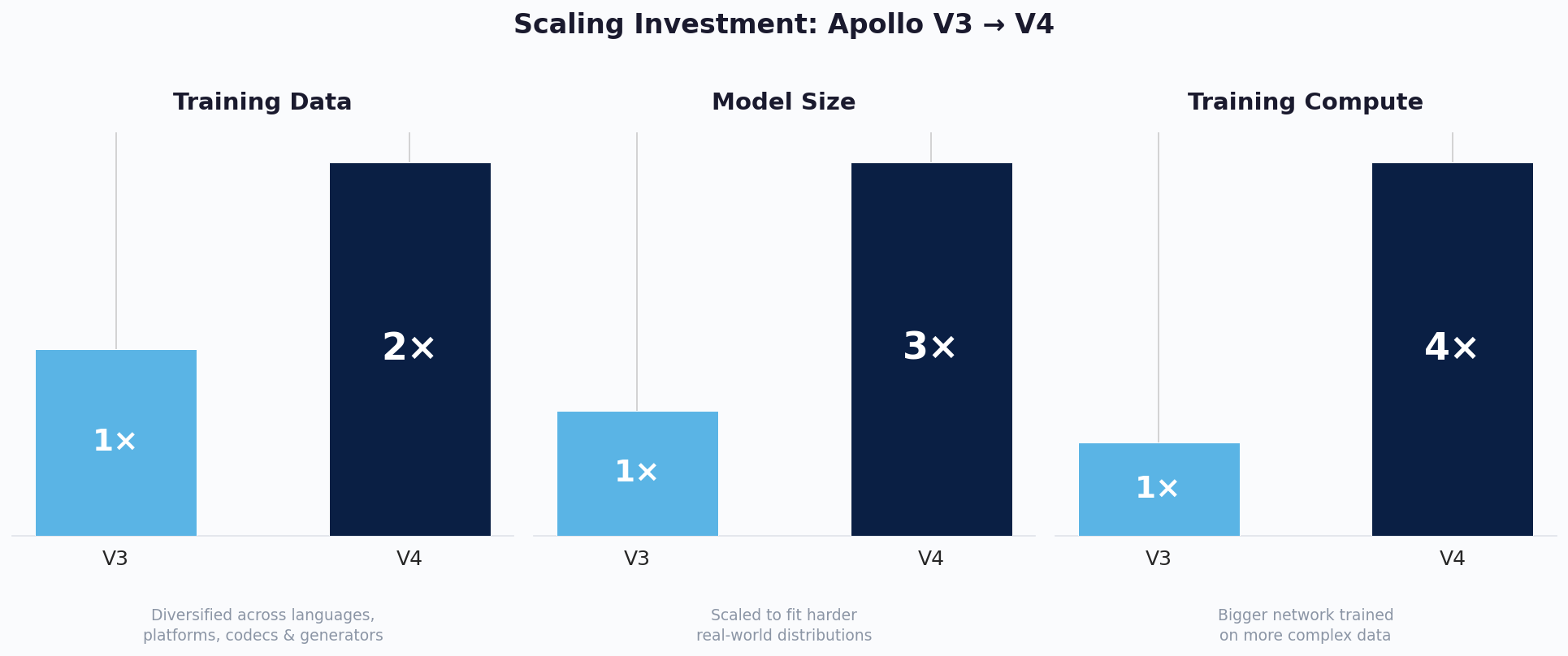
In practice, audio rarely arrives clean. It passes through the processing pipelines of Microsoft Teams, Google Meet, and Zoom. It gets compressed by different codecs, degraded by unstable network conditions, and mixed with background noise that varies from user to user. These are the conditions a detection model faces every day, and they go far beyond what any standard benchmark tests for. There's also a more fundamental problem with real-world deployment: false positives. When a model flags real audio as fake, even occasionally, users lose trust fast. If someone sees a few false alarms every hour, they stop believing the model entirely. For V4, we set ourselves a clear target: a user should be able to run Apollo continuously for days without a single false positive disrupting their workflow. With Apollo V4, our only competitor was V3 itself. We had already proven Apollo's position at the top of the leaderboard. This time, the goal was to build a model you can use every day without friction. To get there, we scaled across every dimension. We doubled our training data by combining diverse external sources with our own commercially curated internal datasets, expanding coverage across languages, platforms, codecs, and generator types. We tripled the model size to give it the capacity to learn harder patterns in this more complex data. And we quadrupled training compute to bring it all together, training the larger network thoroughly on the richer dataset.
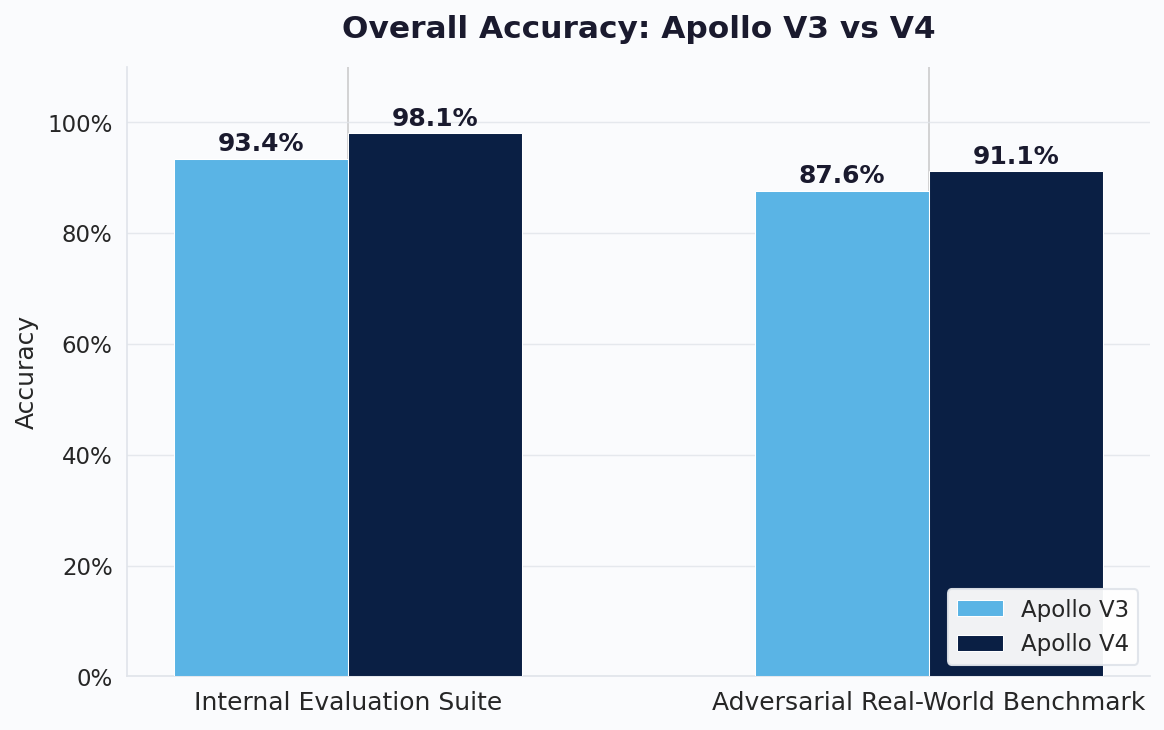
Deepfake technology doesn't stand still, and neither does our evaluation. Since V3, new generators have emerged, attack methods have grown more sophisticated, and we've expanded our understanding of what real-world deployment actually demands. Our evaluation suite has evolved alongside these challenges, growing significantly more comprehensive. Where our V3 benchmarks focused primarily on known public datasets, our current evaluation covers far more ground: more generators, more languages, more recording conditions, and critically, the messy real-world scenarios that public datasets don't capture. This means the 93.4% V3 score here is not comparable to the 98%+ we reported in our V3 blog. The bar itself has moved. We are testing against a much harder and more representative set of conditions. On this Internal Evaluation Suite, which combines well-known public datasets with real daily usage data we collected internally across a competitive mix of generators, languages, and recording conditions, V4 reaches 98.1%. For most users in typical day-to-day usage, where audio conditions fall within this range, perceived accuracy will be above 99%. To push even further, we constructed an Adversarial Real-World Benchmark that deliberately concentrates the hardest edge cases into a single evaluation: meeting app recordings, re-recorded audio, phone calls, voice cloning, and diverse background conditions. Even on this intentionally extreme benchmark, V4 lifts accuracy from 87.6% to 91.1%. But these top-level numbers only capture the summary. To understand where V4 truly shines and why it feels so different in daily use, we need to look deeper into the individual challenges that make real-world detection hard.
Conquering Real Time Communication
One of the biggest challenges in real-world deepfake detection is that audio almost never arrives directly. Most professional conversations happen through meeting applications, and each platform applies its own audio processing pipeline before delivering sound to the other side. Microsoft Teams, Google Meet, and Zoom all handle audio differently, applying noise suppression, automatic gain control, and compression in their own way. What makes this even harder is that these pipelines aren't static. The processing changes depending on network conditions, whether video is turned on or off, volume settings, and even the number of participants in the call. To illustrate this problem, we ran a simple experiment. We fed a chirp signal, a tone that sweeps across all frequencies with equal power, from one device into a meeting call and recorded what arrived on the other side. In an ideal world, the output would look identical to the input: a flat line across all frequencies. What we actually measured was far from that. Microsoft Teams sharply cuts everything above roughly 8 kHz, losing more than 50 dB of signal in the upper frequencies. Google Meet preserves more bandwidth but introduces a stepped attenuation pattern, gradually losing power above 8 kHz before dropping off completely around 15 kHz. Both platforms also attenuate the lower frequencies compared to the original signal, and the distortion patterns between them are different. The plots below show just one configuration: two participants, medium volume, no video. In our full analysis, we observed that every change in meeting settings, turning video on, adjusting volume, adding participants, produces a different transfer function. A deepfake detector that isn't built to handle this variability will either miss fakes hidden behind platform distortion or, worse, flag perfectly real meeting audio as suspicious.
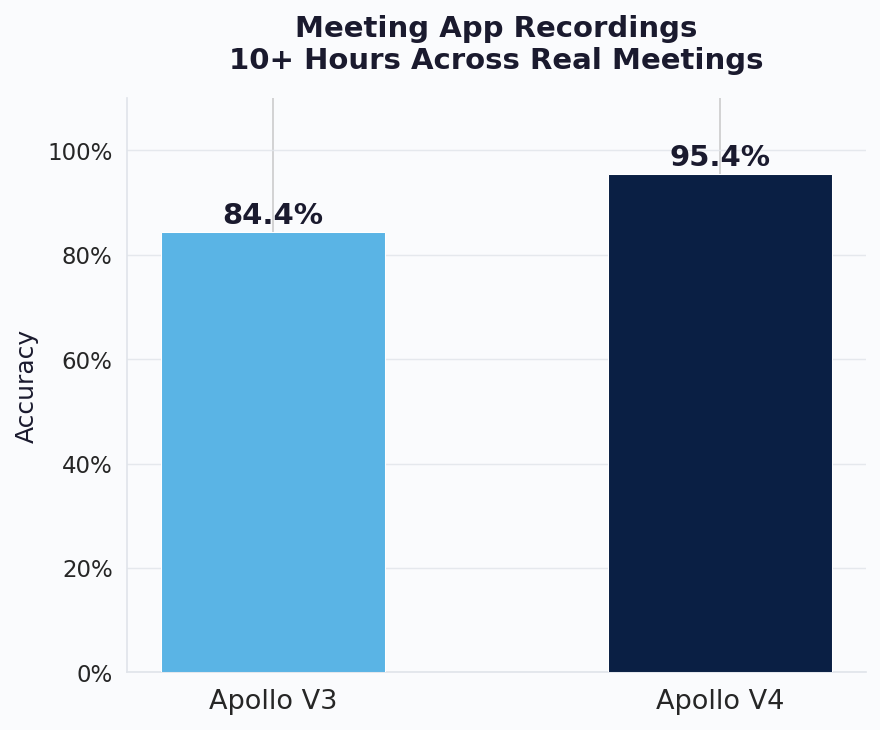
To measure this improvement directly, we created our own internal test dataset by recording over 10 hours of real meetings across multiple platforms including Teams, Meet, and others. This is not a curated friendly test set. It includes a wide range of challenging conditions: different numbers of participants, varying network quality, video on and off, mixed microphone setups, and real background noise from actual work environments. We intentionally kept the messiest recordings in the dataset rather than filtering them out. On this deliberately tough evaluation, V4 reaches 95.4% accuracy compared to 84.4% for V3, an 11-point improvement. In cleaner meeting conditions, which represent the majority of real daily usage, V4's accuracy is significantly higher. The 95.4% figure reflects the average across all conditions including the worst ones, making this one of the most impactful improvements in V4 for everyday use.
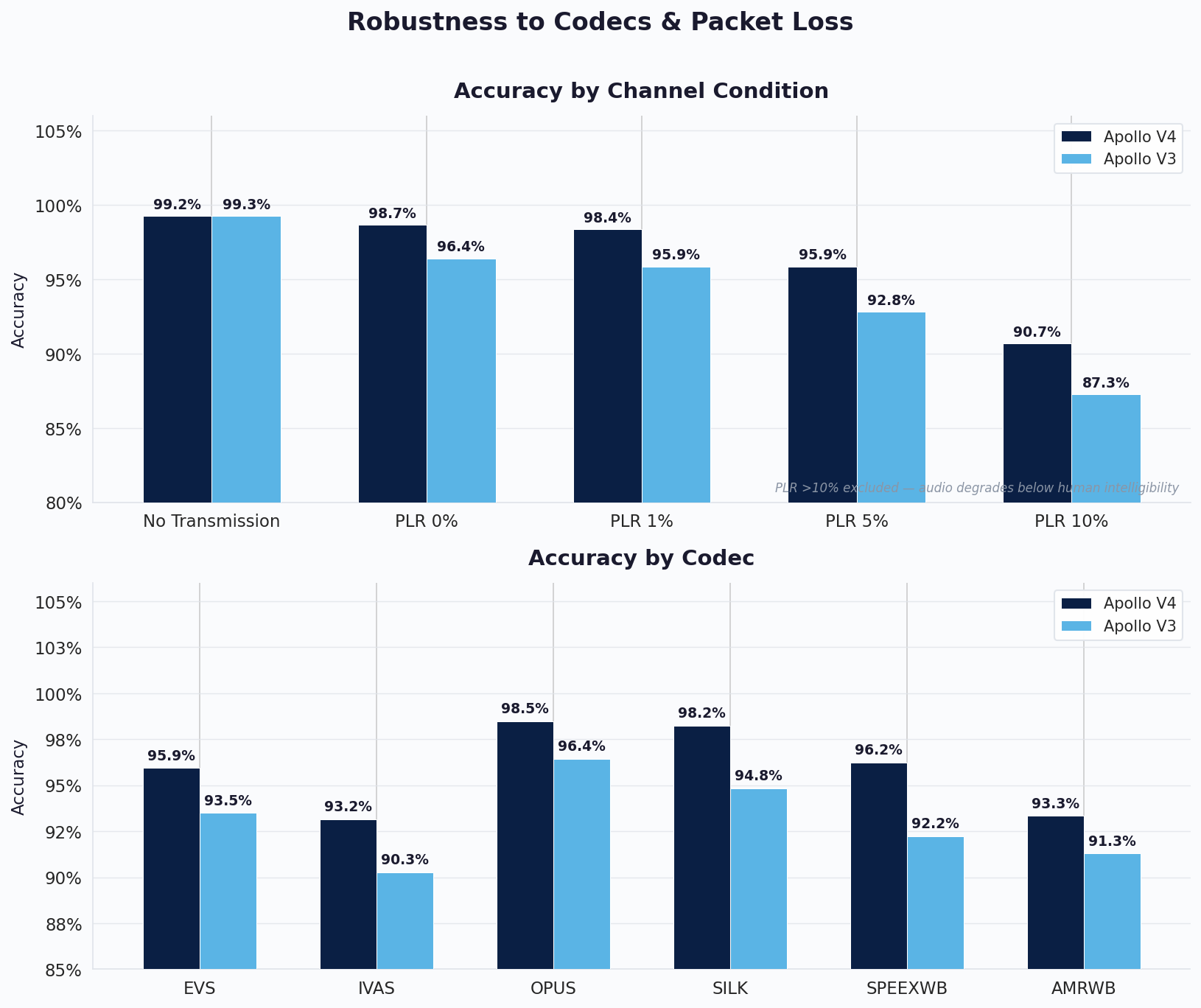
On top of the meeting application's own processing, real-time communication also involves audio codec compression and network transmission. Each call encodes audio through a codec like Opus, SILK, or EVS, and the signal may lose packets along the way depending on network stability. The combination of different codecs and varying network conditions creates yet another source of variability that a detection model needs to handle.
We tested V4 across six widely used codecs at packet loss rates ranging from 0% to 10%. The first chart shows accuracy at each packet loss level, averaged across all codecs. The second shows accuracy for each codec individually, averaged across all packet loss conditions. This gives a complete picture of how the model handles the full combination of codec compression and network degradation. V4 outperforms V3 in every condition, and the gap widens as things get worse. At 10% packet loss, where audio already starts sounding noticeably degraded to human listeners, V4 still holds 90.7% compared to 87.3% for V3. The improvement is consistent across every individual codec as well. It's important to put these numbers in context. The evaluation here deliberately spans the entire range of network conditions from perfect to severely degraded, and averages them all together. In typical real-world usage, where packet loss is minimal and codec quality is high, V4's accuracy on codec-transmitted audio is well above 99%. The numbers shown here are pulled down by the extreme end of the spectrum, conditions that are uncommon in everyday communication but essential to test for robustness.
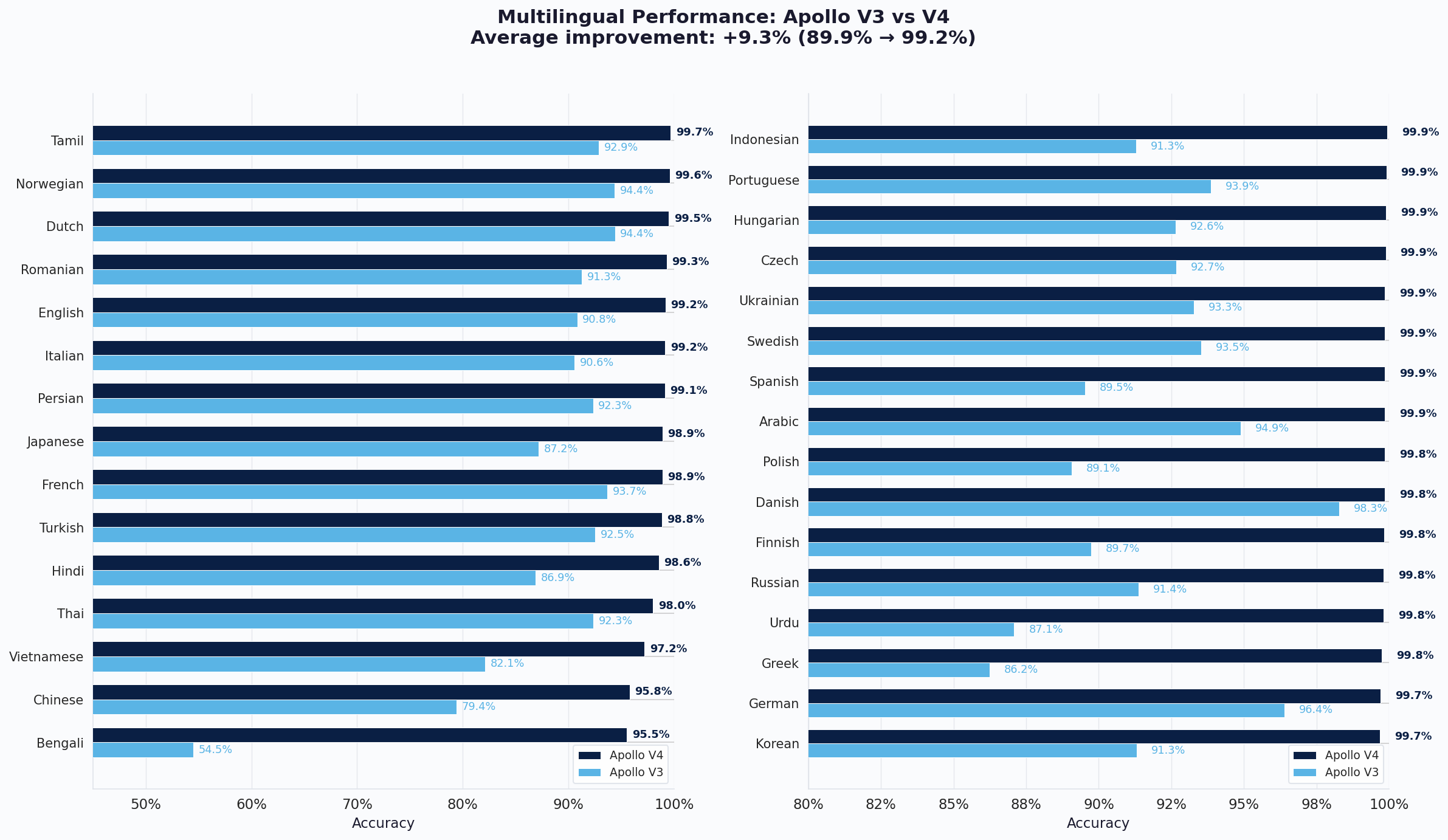
Multilingual Performance
Audio deepfakes are not limited to English. To make Apollo truly multilingual, we expanded our training set with over 300 new language and dialect sources from underrepresented regions around the world. This new data didn't just add language coverage. Because it was collected from diverse real-world environments, it also brought in a wider variety of microphones, recording conditions, and background noise profiles, which helped the model generalize better even on languages it had already seen. Models trained on a narrow set of languages tend to develop a bias, performing well on well-represented languages while struggling on others. By significantly diversifying our training data, V4 overcomes this limitation. The result is a model that is effectively language-agnostic, detecting deepfakes based on the acoustic properties of the audio itself rather than relying on language-specific patterns. We evaluated V4 across 31 languages on a challenging multilingual test set. The average accuracy improved from 89.9% to 99.2%, a gain of 9.3 points, with every single language now exceeding 95% accuracy.
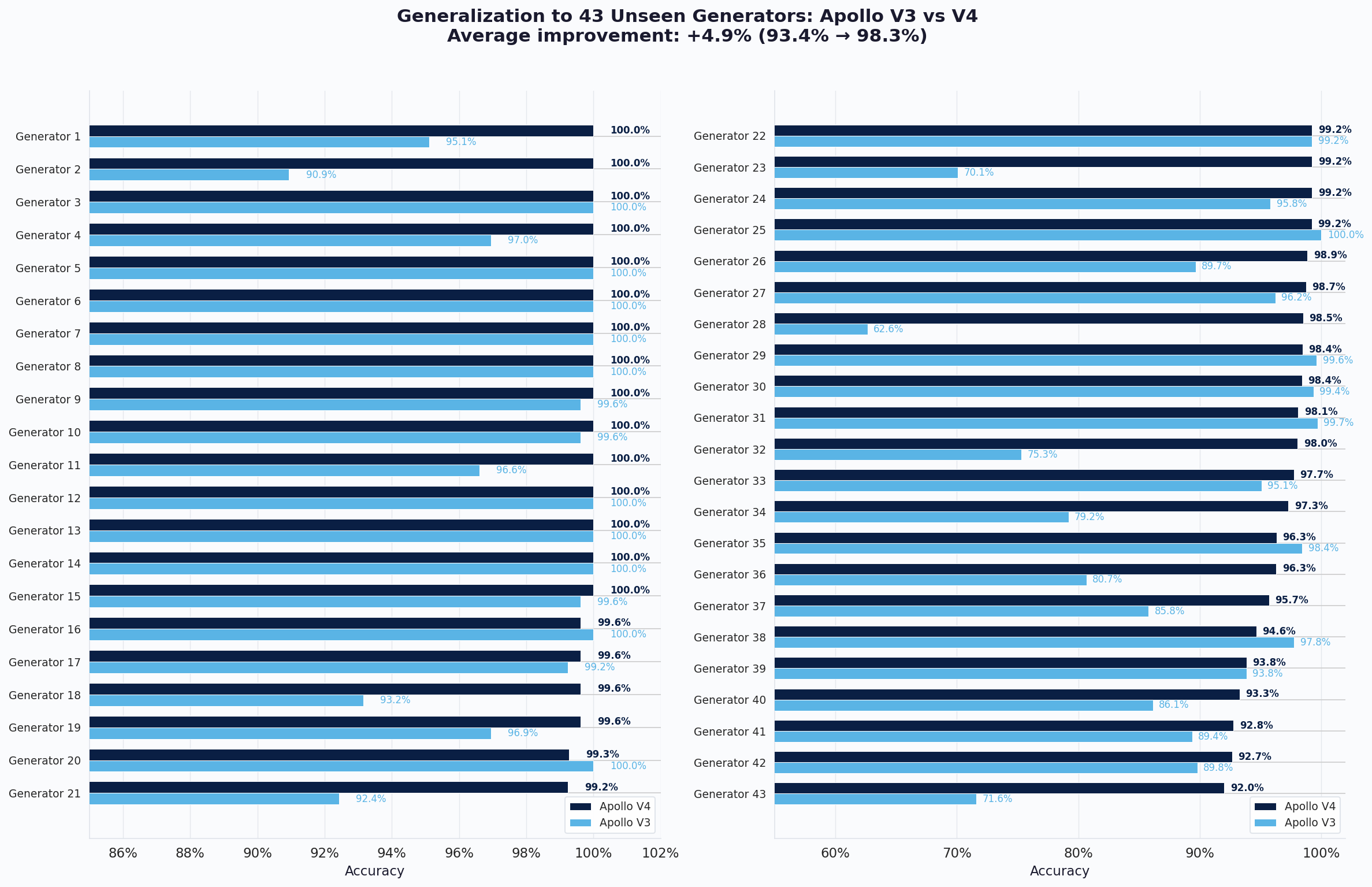
Generalization to Unseen Generators
To show that V4's improvements extend beyond the languages and generators it was trained on, we evaluated it on 43 additional generators that were not part of its training data. Across all of them, V4 averages 98.3% accuracy compared to 93.4% for V3. V4 scores above 92% on every single generator, and its lowest result still exceeds V3's average. This confirms that V4's improvements are not specific to any one generator but reflect a broadly more robust model.
Conclusion
With Apollo V4, our focus was clear: build a model people can rely on every day without friction. On our internal evaluation suites covering over 300 languages, diverse meeting applications, network conditions, and adversarial scenarios, V4 achieves 98.1% accuracy on our Internal Evaluation Suite and 91.1% on our Adversarial Real-World Suite. Performance on meeting application recordings improved by 11 points, directly addressing the most common pain point in daily use. Robustness to codecs and network degradation improved consistently across all conditions up to 10% packet loss, the realistic range for live communication. Multilingual accuracy increased by over 9 points on average across 31 languages, effectively eliminating the language bias that limited earlier models. On 43 unseen generators, V4 averages 98.3% accuracy. Apollo V4 isn't just a better model on paper. It's a better experience in practice. Looking ahead, our goal is to push accuracy above 99% against any form of adversarial attack and to reach 99.999% reliability in real-world deployment, so that when Apollo flags an audio file, people can trust that result without hesitation and take action to verify the source. We are also working on bringing explainability to our models, enabling forensic teams to understand not just whether audio is fake, but why the model reached that conclusion.



